Orientação para modelagem de dados
A Administração de Dados em uma instituição é uma área que deve ter uma ampla atuação e andar em conjunto com a área de Desenvolvimento de Sistemas.
A Administração de Dados tem como objetivo principal fazer a gestão do modelo de dados corporativo da instituição, promovendo sua conceituação, segurança, integridade, compartilhamento e qualidade.
Para isso a administração de Dados deve atuar de forma à:
- Conhecer o negócio da empresa de forma, a saber, as áreas que utilizam os dados, considerando o nível de acesso que cada um terá do dado;
- Modelar os dados corporativamente;
- Respeitar as múltiplas visões e utilizações de um mesmo dado;
- Disponibilizar os dados de forma organizada;
- Compartilhar os dados evitando redundância;
- Servir como base para a construção de sistemas de informações flexíveis, integrados e eficientes.
Para isso temos que:
Administração de Dados e a Equipe de Desenvolvimento trabalhem em parceria e com uma boa documentação do projeto.
Assim o modelo de dados pode ser construído / mantido a “4 mãos”, mas sempre pensando em sua qualidade, pois isso é é imprescindível para que o Ministério da Saúde possa prestar seus serviços ao cidadão.
Modelos de dados com qualidade
Para que um modelo de dados seja considerado de boa qualidade, deve atender aos requisitos funcionais do projeto a que se propõe atender, seguir as boas práticas de modelagem de dados e ser bem documentado. Então para que um modelo seja considerado de qualidade, seguindo as boas práticas, os seguintes indicadores devem ser considerados.
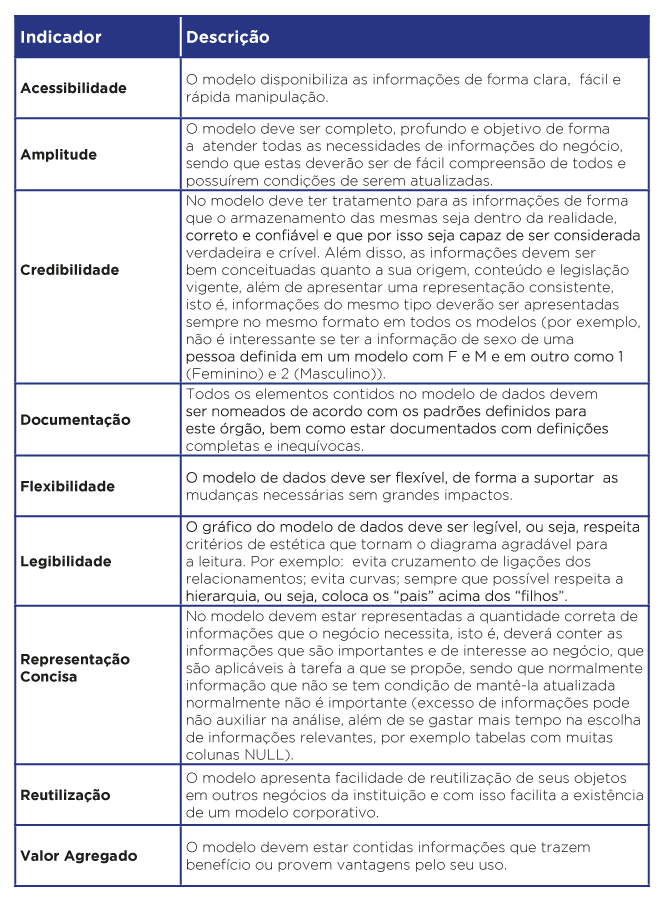
Começaremos agora a descrever as regras técnicas para que possamos ter modelo de dados de qualidade, procurando obter um uso de objetos de banco de dados e como já foi dito, devem obrigatoriamente ser seguidas.
- Primary Key (PK)
Toda tabela deve ter uma primary key para identificação única do registro, que pode ser um sequencial (controlada por uma sequence do banco de dados) que não tem significado negocial, ou uma chave negocial, simples ou composta. No cado da PK ser um sequencial, é interessante que se defina uma UK como chave negocial da tabela, por exemplo, em uma tabela de pessoas fícicas a chave negocial seria o nº do CPF. O Não atendimento deste item contraria os indicadores de qualidade e acessibilidade, reutilização e amplitude.
- Foreign Key (FK)
Uma ou mais colunas que são geradas por um relacionamento com a tabela detentora destas colunas e mais outra tabela, que vai determinar os valores possíveis para estas colunas. Em uma FK podemos ter uma coluna ou mais de uma (chave composta). No caso de chave composta é interessante que as colunas tenham preenchimento obrigatório, pois o SGBD somente realiza a verificação de integridade quando todas as colunas estiverem preenchidas. O não atendimento deste item contraria os indicadores de qualidade acessibilidade e credibilidade.
- Constraint para coluna NOT NULL
Para essas constraints não há necessidade de se definir um nome, pois estas são criadas automaticamente pelo banco de dados. O não atendimento deste item contraria o indicador de qualidade documentação.
- Constraint default de coluna
Para colunas se requer um valor padrão para o preenchimento da mesma quando não é definido nenhum valor na inclusão de uma linha na tabela. Nestes casos a coluna deve ter seu preenchimento obrigatório, para que este valor default seja utilizado, como pode ser visto na seguinte tabela.
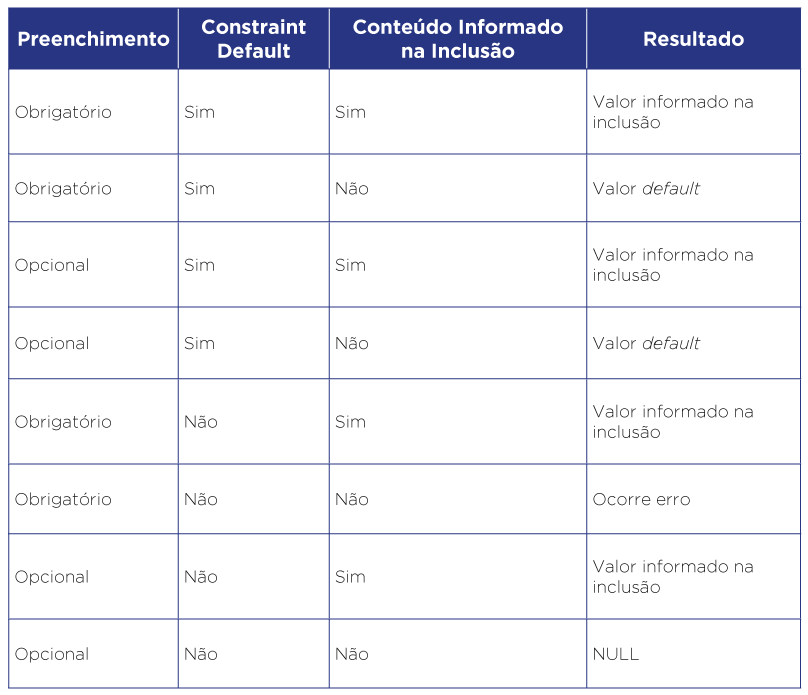
É importante ressaltar que o valor default é obrigatório somente nos casos de criação de coluna com preenchimento obrigatório em tabela já existente.
Para essas constraints não há necessidade de se definir um nome, pois estas são criadas automaticamente pelo banco de dados.
O não atendimento deste item contraria os indicadores de qualidade acessibilidade e documentação.
Lista de valores
Esta situação se refere a colunas que possuem um domínio definido, por exemplo, estado civil, tipo sanguíneo, tipo de pessoa, situação de contrato, etc. É importante ficar claro que nestas situações é imperativo que:
- Haja a implementação de controles com os valores válidos constantes na lista, que pode ser por check constraint (CK) ou tabela de domínio, conforme regras definidas neste item;
- Todos os valores devem ter o significado de cada um definido e documentado, pois isso diminui os problemas com informações sem credibilidade por falta de entendimento dos dados armazenados na base de dados.
Então para a implementação de lista de valores devem ser seguidas obrigatoriamente as s regras descritas a seguir.
1. Devem ter preenchimento obrigatório.
O preenchimento obrigatório é importante, pois NULL não é um valor pré-definido e sim ausência de valor. Acrescentando-se que registros com NULL prejudicam a performance de consulta, pois estes não são considerados em index.
Além disso, na obtenção de indicadores que envolvam essas colunas de domínio com valores NULL, esses registros também não são considerados.
Nos casos onde é necessário NULL, deve-se definir como valor no domínio, a coluna preenchida totalmente com o dígito 9, seja para datatype numérico ou de caracter. Por exemplo:
- Coluna numérica de tamanho 1, o valor correspondente deve ser 9;
- Coluna numérica de tamanho 2, o valor correspondente deve ser 99;
- Coluna numérica de tamanho 3, o valor correspondente deve ser 999;
- Coluna caracter de tamanho 1, o valor correspondente deve ser ‘9’;
- Coluna caracter de tamanho 2, o valor correspondente deve ser ‘99’;
- Coluna caracter de tamanho 3, o valor correspondente deve ser ‘999’.
A descrição do valor deve ser definida da forma mais adequada ao negócio que está atendendo.
2. Utilizar CK com a definição dos valores do domínio:
- Domínio possui dois valores e mais o valor para NULL conforme descrito acima;
- Os valores contidos na lista devem indicar que são estáveis, isto é, que a lista não vai aumentar;
- Para o caso da CK depender do conteúdo de uma outra coluna da tabela, deve ser criada uma CK da tabela;
- No comentário do campo, onde é descrita a sua finalidade, é obrigatório que contenha cada valor e a descrição do significado de cada um.
Na situação aqui indicada é obrigatório o uso de uma CK.
3. Domínio Sim ou Não
Para colunas cujo conteúdo deve expressar Sim ou Não, os valores do domínio devem ser S ou N, respectivamente.
4. Utilizar uma tabela de domínio, quando o domínio não se encaixa nas situações relacionadas com indicação de uso de CK.
5. Como incluir dados em tabela de domínio?
- Para tabelas do DBGERAL, a responsabilidade é da DAAED;
- Para tabelas de negócio temos as seguintes situações:
- Manutenção de dados em tabela que não tem impacto no negócio e pode ter muitas alterações: o indicado é que o sistema tenha telas para manutenção das tabelas;
- Manutenção de dados em tabela que não tem impacto no negócio e que o previsto é que praticamente não haja alterações em seu conteúdo: o indicado é que o sistema não tenha telas para manutenção das tabelas (atualização por script);
- Manutenção de dados em tabela que tem impacto no negócio: o indicado é que o sistema não tenha telas para manutenção das tabelas, até porque em caso de alterações no conteúdo, a equipe responsável precisa analisar o impacto no sistema.
O não atendimento deste item contraria os indicadores de qualidade acessibilidade, credibilidade e flexibilidade.
Date x Timestamp
A utilização desses datatypes as vezes causa um pouco de confusão. Quando devo usar cada um?
Utilize o DATE quando é necessário apenas a DATA ou DATA e HORA com precisão de segundos.
Utilize o TIMESTAMP quando é necessário DATA e HORA com precisão de milissegundos ou para utilização de timezone. O timezone é apropriado quando é necessário exibir informações de data e horários usando o fuso horário do sistema cliente.
Tabelas de Auditoria
Tabelas que permitem efetuar um rastreamento de qualquer operação que ocorre nos dados de uma tabela. Para que uma tabela de auditoria seja eficaz, deve responder quem fez a operação, quando foi feita e o que foi feito. A GAAD possui um padrão de auditoria, que responde a essas perguntas. As tabelas que devem ser auditadas são:
- As que possuem privilégio de DELETE, sendo neste caso obrigatório. Caso a tabela e trigger não sejam criadas, o privilégio de DELETE não será fornecido, ou se já existe, será retirado.
- Outras tabelas sem privilégio de DELETE, o usuário decide quais devem ser auditadas (normalmente por possuírem dados críticos para o Ministério da Saúde).

Mas então como proceder para sistemas legados em que a equipe decide por utilizar a nova estrutura:
- Se não há auditoria, a AD deve criar a auditoria no padrão da AD.
- Se há auditoria em outro formato, a AD deve sugerir a utilização do padrão da equipe, mas a decisão é da equipe responsável pelo aplicativo. Nunca se esquecer, que na criação da uma nova auditoria para uma tabela, a trigger da antiga deve ser desabilitada.
- Para projetos novos deve ser adotado o padrão da AD.
A estrutura da tabela de auditoria no padrão da AD possui as mesmas colunas da tabela origem e mais as de controle, conforme definido na seguinte tabela:



1. gera a auditoria para a tabela informada
O AD deve enviar a linha de comando a seguir para que o DBA a execute e gere a auditoria para os casos em que há necessidade de que uma tabela tenha auditoria.
2. atualiza a auditoria para a tabela informada
O AD deve enviar a linha de comando a seguir para que o DBA a execute e atualize a auditoria.
Mas atenção nos casos de RENAME de coluna, se a package for executada diretamente, será incluída uma nova coluna com o novo nome. Então nessas situações o correto é executar o comando para renomear a coluna na tabela de auditoria à é bom que o AD passe esse comando para o DBA.
Comandos que devem ser inseridos na aplicação para obtenção do usuário final e IP da máquina que esse usuário está logado. Procure sempre orientar as equipes de desenvolvimento.
- Login/Identificador do usuário como parâmetro EXEC
- IP do usuário como parâmetro
3. para geração dos scripts dll de um esquema completo (todas as tabelas de um schema)

4. para verificação de estruturas desatualizadas em um esquema

5. observações importantes:
- Campos BLOB não são auditados, para o caso de tabelas que ainda possuem campos desse tipo.
- Na exclusão de colunas da tabela origem, estas não são excluídas da tabela de auditoria, pois esta visa manter o controle das informações existentes e as que já existiram na tabela de origem.
- Tabela de auditoria não deve possuir constraint, pois as restrições de integridade devem ser garantidas pela tabela origem.
- Quando uma tabela de auditoria nos padrões da GAAD é criada, é importante comunicar a necessidade dos comandos que devem ser inseridos na aplicação.
Para tabelas que devem ter auditoria, o não atendimento deste item contraria o indicador de qualidade credibilidade.
Tabelas de histórico
Tabela utilizada para armazenar os dados históricos para atender de uma determinada funcionalidade necessária para o negócio. Diferentemente de tabelas de auditoria, não há necessidade de que as tabelas com dados históricos possuam todas as colunas da tabela de origem. A definição de quais colunas devem fazer parte da tabela de histórico deve constar nos requisitos no aplicativo, assim como a forma de manutenção de seus dados, que pode ser por trigger ou pelo próprio aplicativo. O não atendimento deste item não contraria nenhum indicador de qualidade, mas é importante observar bem a diferença entre histórico e auditoria.
Tabelas associativas
Uma tabela associativa representa uma entidade que não existe por si só e sua existência está condicionada à existência de duas ou mais entidades com relacionamento do tipo N:N. Além disso, o identificador negocial da tabela é formado exclusivamente pelas colunas que são geradas pela FK dessas tabelas relacionadas. Vale ressaltar que mesmo que estas tabelas possuam atributos próprios devem ser tratadas como associativas (tabelas com prefixo RL_ ou TL_) Conforme Anexo I, o não atendimento deste item contraria o indicador de qualidade documentação.
Exclusão lógica
Para o caso de tabelas com exclusão lógica, é importante verificar qual será o mecanismo de controle quanto ao uso de registros que estejam marcados como “Excluídos”, isto porque estes registros não podem ser utilizados. Sendo assim, ou a aplicação deve tratar isso ou então devem ser implementadas triggers nas tabelas que recebem FK dessas tabelas com exclusão lógica, de forma, que os registros marcados como excluídos não seja mais utilizados. Mas o que é importante de observar é que a exclusão lógica de uma tabela deve ser tratada por um coluna, onde o nome obrigatoriamente é ST_REGISTRO_ATIVO com datatype VARCHAR2(1) e preenchimento obrigatório. Além disso, deve possuir uma check constraint com os valores ‘S’ ou ‘N’ e a descrição pode ser “Indica se o registro está ativo ou não (excluído logicamente). O seu domínio é: S – Sim (está ativo) ou N – Não (não está ativo). O controle no uso de registros excluídos deve ser feito pela aplicação.”. Uma observação importante é que quando a tabela é criada já com essa coluna, não é obrigatório a definição de um valor DEFAULT, mas quando a coluna é adicionada em uma tabela já existente, deve-se definir o valor DEFAULT, pois assim a coluna pode ser criada como NOT NULL e o valor DEFAULT será preenchido para todos os registros existentes na tabela. O não atendimento deste item contraria os indicadores de qualidade acessibilidade e documentação.
Index
A criação de index deve ser feita visando uma melhoria de performance em consultas ao banco de dados, sendo que isso é possível na criação de index adequados. Outra forma de termos performance melhor é ter uma melhoria de hábitos de forma a produzirmos os comandos SQL mais eficientes que implicarão em respostas mais rápidas para os usuários dos sistemas e uma melhoria no funcionamento dos bancos de dados, mas este será um assunto para ser tratado posteriormente. A criação de index deve ser bem planejada, pois eles ajudam nas consultas, mas em inclusões, atualizações e deleções de registros, eles também são atualizados e com isso há uma perda de performance nessas operações. Então a criação de index deve ser feita de forma a sejam bem utilizados nas consultas e tragam bons ganhos de performance, que valha a pena o tempo perdido nas atualizações.
Sendo assim a criação de index é importante quando:
1. Uma coluna é referenciada em um comando SQL de consulta na cláusula de restrição (filtro), através de:
- Uma igualdade: sg_uf = ‘DF’;
- Comparação com intervalo ilimitado: nu_vaga > 100;
- Comparação com intervalo limitado: nu_vaga between 100 AND 200.
2. Para ORDER BY ou GROUP BY é bom que tenhamos um index considerando todas as colunas envolvidas e na ordem em que são especificadas nessas cláusulas (é bom que estas colunas tenham valores preenchidos, pois colunas com NULL não são consideradas em index). No caso do ORDER BY é melhor que as colunas sejam NOT NULL;
3. Utilizando-se MAX ou MIN, desde que a função faça parte da seleção e esteja sozinha, pois em caso contrário o index não é utilizado;
4. Para colunas que são FK, desde que estas não tenham pouca variação de valores, por exemplo, colunas de domínio;
5. Na utilização de OR na cláusula de junção / restrição, deve-se ter index em todas as colunas envolvidas no OR;
6. Quando se fizer uso de função na cláusula de junção / restrição, definir um index baseado em função;
7. O uso de consultas envolvendo na cláusula de restrições campos textuais deve ser evitado. Caso seja inevitável e o SGBD for o Oracle, utilizar index Intermedia Text (para campos VARCHAR2, CHAR e CLOB).
O não atendimento deste item contraria o indicador de qualidade acessibilidade.
Triggers
O uso de triggers para implementação de regras de negócio é aconselhável evitar, sendo interessante a utilização para auditoria, histórico e garantia de integridade quando não é possível a implementação por constraints. Nos casos de uso de Trigger em implementação de regra de negócio do aplicativo, a responsabilidade é da equipe de sustentação. O não atendimento deste item contraria os indicadores de qualidade acessibilidade e credibilidade.
Views
O uso de view tem como objetivo facilitar a visualização dos dados, sendo que com elas é possível simplificar comandos com colunas resultantes de agrupamentos de dados de mais de uma tabela, cálculos, quando há necessidade de inibir colunas ou linhas de tabelas, por questões de segurança, etc. Sendo assim, o uso de views é interessante quando se quando se tem uma consulta de uso frequente, consultas complexas, para restringir o acesso a visualização de dados. Conforme Anexo I, o não atendimento deste item não contraria nenhum indicador de qualidade, mas deve-se ter parcimônia no uso de views e observar a real necessidade do uso de view.
View materializada
Tipo especial de view com característica com armazenamento de dados próprio, originados de uma ou mais tabelas. Bastante utilizadas para facilitar consultas sem impactar na performance das tabelas transacionais. Também permite tratamento de regras negociais e criação de index, diferentemente das views convencionais. Conforme Anexo I, o não atendimento deste item contraria o indicador de qualidade.
Campo BLOB
Quanto ao uso de campos com tipo BLOB, o armazenamento não deve ocorrer em base de dados, mas sim utilizando a tecnologia NFS (Network Fife System). Havendo a necessidade de armazenar o nome do arquivo e a descrição do local de armazenamento na base de dados, devem ser utilizados campos com prefixo NO (nome) e DS (descrição, respectivamente. Para o armazenamento em filesystem, a equipe de responsável pelo aplicativo deverá procurar a equipe de Infraestrutura para obter as devidas orientações. Para maiores informações consultar o memorando n° 32/2016/CGAM/DATASUS/SE/MS, SIPAR 2500.083574/2016-10 e Nota Técnica nº. 063/2016/Infraestrutura/DATASUS. O não atendimento deste item não contraria nenhum indicador de qualidade.
Normas para a modelagem relacional
Um modelo de dados deve estar de acordo com as “Normas Técnicas” definidas acima e mais as normas de modelo relacional definidas a seguir.
Estas normas apresentam boas práticas.
a) Sempre que for identificada a existência de tabelas distintas com muitas propriedades, atributos e relacionamentos em comum, recomenda-se avaliar a possibilidade de aplicar o conceito de generalização / especialização.
b) Em princípio, as tabelas deverão ser modeladas respeitando-se as regras de normalização. Desnormalizações poderão ser feitas desde que haja justificativa técnica da sua necessidade, como por exemplo, para facilitar o acesso às informações e/ou para melhoria de performance. No entanto, para qualquer desnormalização deverá haver um procedimento implementado no banco de dados que garanta a integridade da informação. As justificativas para tais procedimentos deverão ser documentadas na ferramenta case.
c) Em princípio todas as tabelas deverão possuir PK. Para os casos de tabelas em que a Primary Key é uma coluna sequencial, não temos a garantia de unicidade de registros de forma negocial e para essas situações deverá ser verificada a existência de pelo menos uma Unique Key (UK) composta ou simples. Nessa verificação não são levadas em consideração tabelas de apoio, log e temporárias.
d) O relacionamento entre as tabelas deverá ser feito através da criação de chave estrangeira (FK). Excepcionalmente, quando isso não for possível, deverá ficar documentado na tabela o motivo e a forma que será utilizada para garantir a integridade dos dados, devendo ser observado o item que trata de Primary Key no documento.
e) As tabelas mais volumosas deverão ser estudadas de forma a se decidir a criação de índices, bem como outras questões físicas como por exemplo, particionamento.
f) Tabelas com muitas colunas sem preenchimento obrigatório deve-se avaliar real necessidade de tais colunas ou até da tabela. Havendo a necessidade de se manter essa ocorrência, deve haver uma justificativa técnica e esta documentada.
a) Toda coluna cujo conteúdo é uma lista de valores deve ter seu domínio definido.
b) Colunas cujo conteúdo é uma lista de valores implementada por FK com tabela de domínio ou CK devem possuir preenchimento obrigatório, pois para colunas desse tipo não se deve admitir ocorrência nula, visto que o nulo não é um valor pré-definido e sim ausência de valor.
c) Colunas cujo conteúdo representam a mesma informação em modelos diferentes devem possuir o mesmo tipo/tamanho e lista de valores quando for o caso.
a) As tabelas e colunas devem estar documentadas conforme definido neste documento.
b) No caso de ausência de constraint onde deveria existir, deve ser verificado motivo desse tipo de ocorrência e caso seja necessário a não alteração, isso deve possuir uma justificativa técnica e ser documentada.
c) O desenho gráfico do modelo de dados deve possuir estética agradável com utilização de cores para diferenciar módulos funcionais e tabelas compartilhadas de outros modelos, além do que deve ser evitado o cruzamento de linhas.
dar preferência a:
- acrônimo e abreviaturas devem ter pelo menos 2 caracteres;
- a abreviatura deve ter no máximo dois terços do tamanho da palavra original;
- apenas aquelas que tenha no total mais de 8 caracteres podem ser abreviadas;
- se a palavra, termo ou nome não tiver uma sigla /acrônimos conhecidos, use as diretrizes abaixo para construir a abreviatura:
- não devem ser utilizadas preposições, e na necessidade de se utilizar verbos, utilize no presente;
- sempre que possível, evitar o uso de abreviaturas/acrônimos, pois prejudicam o entendimento;
- abreviaturas comumente usadas em português à abreviaturas de negócio;
- abreviaturas de negócio à termos de tecnologia da informação;
- termos da tecnologia da informação à criação de novos;
- criar abreviaturas evitando ambigüidade;
Regra geral para criar novas abreviaturas para palavra:
- escrever a primeira sílaba e a primeira letra da segunda sílaba, ex.: gramática=gram; portugues=port; numeral=num;
- se a segunda sílaba iniciar por duas consoantes, escrever as duas, ex.: construção=constr; secretário=secr;
- se a abreviatura resultante coincidir com uma existente ou sugerir ambigüidade, escrever a segunda sílaba completa e incluir a primeira letra da terceira sílaba, ex.: profissional=profiss;
- qualquer nova abreviatura deve ser submetida a AD.
a) Nome de qualquer objeto deve estar de acordo com a sua finalidade, sendo que para tabelas e colunas isso deve ser sempre verificado e para outros tipos de objetos, somente aqueles que devem ter o nome representativo de acordo com o negócio, conforme especificado no documento de normas de nomenclatura de objetos de banco de dados.
b) O modelo de dados deve ser aderente aos documentos de especificação do projeto. No caso de situações onde esta regra não é seguida, deve ser documentada a justificativa para tal.
Com as orientações contidas neste documento de “Regras Técnicas” e “Normas para Modelagem de Dados Relacionais”, poderemos ter um modelo com qualidade negocial.
Resta apenas a parte relativa a documentação do modelo de dados denominada “Dicionário de Dados”.
Dicionário de dados
Diretrizes para Documentação de Modelos de Dados
Neste item vamos descrever algumas regras básicas que devem ser seguidas para que possamos ter um bom dicionário de dados que é o “Registro detalhado dos conceitos que compõem um universo pré-definido”.
Portanto é importante entender que “A representação gráfica e denominação dos elementos que compõem um modelo de dados não são suficientes para traduzir todos os conceitos do negócio”.
Para que tenhamos uma boa descrição dos elementos de dados devemos considerar os seguintes fatores: clareza, objetividade, respeito à legislação e normativos, respeito à terminologia da área negocial que está sendo tratada, respeito às normas da língua portuguesa, citação de exemplos.
Quando ele é bem compreendido e gera um metadados de qualidade.
1) Na descrição de uma tabela não deve constar que “armazena dados …”, mas que representa uma entidade negocial, então na descrição da tabela deve ser bem conceituada essa entidade.
2) Na descrição da coluna deve ficar claro o que a coluna representa dentro do contexto da entidade negocial que a tabela representa.
3) Ainda no caso das colunas, se a entidade que a tabela representa estiver bem conceituada, a descrição destas fica simplificada.
Para facilitar, a descrição da tabela é interessante responder as seguintes perguntas.
- O que é a entidade?
- O que faz a entidade?
- Para que serve?
- Quando alguém ou algo passa a ser, ou deixa de ser, um elemento dessa entidade?
- Em caso de tabela de domínio, devem constar exemplos.
- A exclusão é lógica?
Assim a descrição da tabela é formada pelo conjunto dessas respostas. Outro ponto a ser observado é que nem sempre é conseguido responder a todas as perguntas, mas é preciso tentar.
Para que um modelo de dados seja considerado de qualidade, ele também tem que ser bem documentado, ou seja, o dicionário de dados deve conter informação relevante e é obrigatório!
A descrição da tabela e das colunas deve ficar armazenada na ferramenta case adotada pelo DATASUS no local onde será gerado o Comment na geração de script. Dessa forma teremos o dicionário na ferramenta e no banco de dados.
Exemplo de descrições específicas
A seguir temos sugestões de algumas descrições específicas de determinadas categorias de colunas que são muito utilizadas. É importante ficar claro que as descrições utilizadas no modelo não precisam ser exatamente iguais as aqui sugeridas, mas o significado deve ser o mesmo.
ORACLE: “Representa a chave primária sequencial da tabela, que é controlada pela sequence [NomeSequence] do banco de dados específica para a tabela.”
POSTGRE ou MySQL: “Representa a chave primária sequencial da tabela, que é controlada pelo banco de dados através do datatype desta coluna SERIAL.”
[Descrição a finalidade da coluna dentro de contexto da entidade negocial representada pela tabela.] + [A coluna é FK da tabela [NomeTabela].].
[Descrição da finalidade da coluna] + [Domínio] Observação: Entender como domínio, a indicação de todos os valores e a descrição do significado de cada um (semelhante ao ST_REGISTRO_ATIVO).
[Descrição da finalidade da coluna] + [Domínio] Observação: Entender como domínio, a indicação de todos os valores e a descrição do significado de cada um (semelhante ao ST_REGISTRO_ATIVO).
O comentário da tabela de domínio, além da descrição de sua finalidade, deve conter a indicação de todos os valores e a descrição do significado de cada um. Caso o domínio seja composto por mais de 10 valores , indicar exemplos.